Hadoop安装、伪分布式配置、运行WordCount示例程序的指南。
作者使用的环境是64位WSL2 Ubuntu 20.04。
OpenJDK8安装
Hadoop框架是使用Java编写的,因此需要一个与之兼容的Java Runtime Environment (JRE) 和Java Development Kit (JDK)。
当前Apache Hadoop 3.x 完全支持 Java 8。
如果你的环境中已经安装了Java,可以通过下面的指令来检查你的Java版本:
1 | java -version; javac -version |
版本号是1.8开头的即可。
如果没有安装Java的的话,可以执行以下指令安装OpenJDK 8:
1 | sudo apt update |
检查是否安装成功:
1 | java -version; javac -version |
创建一个非Root用户
如果使用root用户启动Hadoop的话会报错(本人就踩过这个坑)。
如果你的环境中已经有可用的非root用户了,但是不想弄乱自己原来的用户环境,也可以按照下面的操作创建一个新的用户(而且这样后面很多步骤可以直接复制指令代码而不用修改)。
创建一个名为hdoop的用户(也可以叫别的名字,不过确保在后面的操作中要统一):
1 | sudo adduser hdoop |
过程中会弹出一些提示,按照提示操作即可。
将hdoop用户加入sudo用户组:
1 | usermod -a -G sudo hdoop |
切换到hdoop用户:
1 | su hdoop |
安装OpenSSH
如果你的环境中已经有可用的ssh,可以跳过这一步。
安装指令:
1 | sudo apt update |
设置无密码SSH
1 | ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa |
使用hdoop用户尝试以下指令,如果能成功连接,则设置成功:
1 | ssh localhost |
这个指令会ssh连接你当前的机器(我连我自己),返回一个新的shell给你,可以用
exit指令退出(不退出也无妨)。
安装Hadoop
作者用的是清华的镜像(链接),里面提供各个版本的hadoop。
这里作者选用的是hadoop-3.3.0文件夹里的hadoop-3.3.0-aarch64.tar.gz文件。这是一个为aarch64平台编译好了的安装包(解压之后就可以直接用)。请根据自己的平台选择不同的版本。
如果你不知道用哪个的话,首选hadoop-3.3.0.tar.gz。
下载安装包(链接请换成你自己选择的安装包对应的链接):
1 | wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0-aarch64.tar.gz |
在安装包所在的路径下解压(文件名当然也换成你自己的):
1 | tar xzf hadoop-3.3.0-aarch64.tar.gz |
这里作者下载和解压都是在用户目录~下执行的,解压之后hadoop的文件就都在~/hadoop-3.3.0路径下了。
如果你是在别的路径解压的,请记好解压出来的文件夹所在的位置,下一节会用到。
配置环境变量
编辑~/.bashrc文件(这里使用vim):
1 | sudo vim ~/.bashrc |
在文件末尾添加以下内容:
1 | #Hadoop Related Options |
HADOOP_HOME那一行的路径换成你自己的hadoop安装路径。
保存并退出。
执行以下命令使得配置立即生效:
1 | source ~/.bashrc |
编辑hadoop-env.sh文件
1 | sudo vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh |
找到文件中含有export JAVA_HOME=的那一行,去掉那一行的注释(即去掉开头的#)
修改该行的内容为:
1 | export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 |
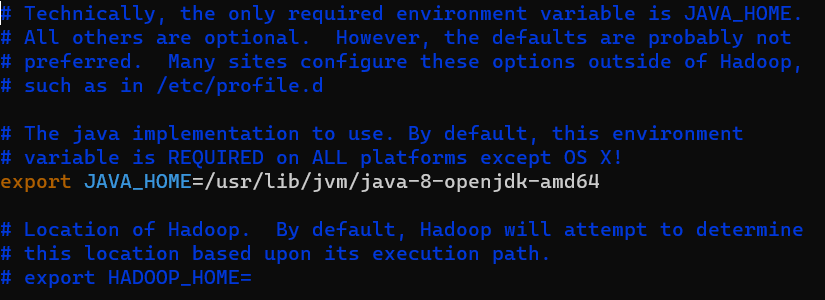
上面的路径值可以换成你自己的java所在的路径。
如果你想定位自己的java所在的路径的话,可以执行以下命令(注意命令里是反引号):
1 | readlink -f `which javac` |

红框里的就是你需要的路径啦。
编辑core-site.xml文件
core-site.xml定义了HDFS和Hadoop core的属性。
为了配置伪分布模式,需要指定NameNode的URL和map reduce过程所用的临时文件夹。
1 | sudo vim $HADOOP_HOME/etc/hadoop/core-site.xml |
将configuration部分改为以下内容:
1 | <configuration> |
然后在/home/hdoop下创建tmpdata文件夹。
1 | mkdir /home/hdoop/tmpdata |
这里创建的文件夹路径和上面的configuration第四行
value里的路径一致。因此你可以把文件夹创建到不同的位置或者叫不同的名字,但是记得在配置文件中更改对应的内容。
编辑hdfs-site.xml文件
这个文件决定了node metadata、fsimage file和edit log file文件存放的位置。
1 | sudo vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml |
和上一节类似,将configuration部分改为以下内容:
1 | <configuration> |
然后创建对应的文件夹/home/hdoop/dfsdata/namenode和/home/hdoop/dfsdata/datanode:
1 | mkdir -p /home/hdoop/dfsdata/namenode /home/hdoop/dfsdata/datanode |
同样,如果你想把目录建在其他位置,记得更改configuration中对应的地方。
修改mapred-site.xml文件
1 | sudo vim $HADOOP_HOME/etc/hadoop/mapred-site.xml |
将configuration部分改为以下内容:
1 | <configuration> |
修改yarn-site.xml文件
1 | sudo vim $HADOOP_HOME/etc/hadoop/yarn-site.xml |
将configuration部分改为以下内容:
1 | <configuration> |
Format HDFS NameNode
1 | hdfs namenode -format |
看到SHUTDOWN_MSG说明该过程结束了。
启动Hadoop集群
1 | start-dfs.sh |
如果出现以下的警告信息可以忽略不管,不会产生实质影响:
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
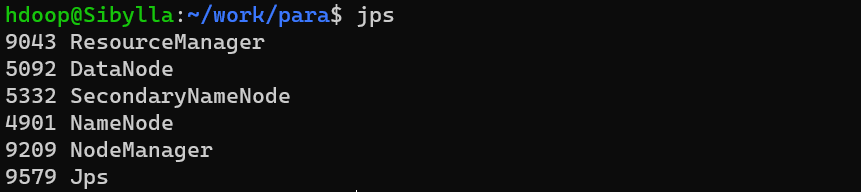
使用下面这个简单的指令检查是否正常启动:
1 | jps |
应该显示有如下几项:
1 | ResourceManager |
运行WordCount示例程序
当然,在此之前你需要先按照上面的步骤启动hadoop集群。
首先要在HDFS中创建文件夹:
1 | hdfs dfs -mkdir -p /user/hadoop/input |
将输入文件拷贝到这个文件夹中:
1 | hdfs dfs -put ~/work/para/input/*.txt /user/hadoop/input |
命令中的
~/work/para/input/*.txt换成你自己的输入文件所在路径。下同。
通过以下指令查看文件是否拷贝,以及内容是否一致:1
2hdfs dfs -ls /user/hadoop/input
hdfs dfs -cat /user/hadoop/input/Input1.txt
编译运行WordCount程序:
1 | export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH |
要注意的是,如果HDFS中指定的输出文件夹已经存在(此处对应的是
/user/hadoop/output/),则会报错。
运行中:
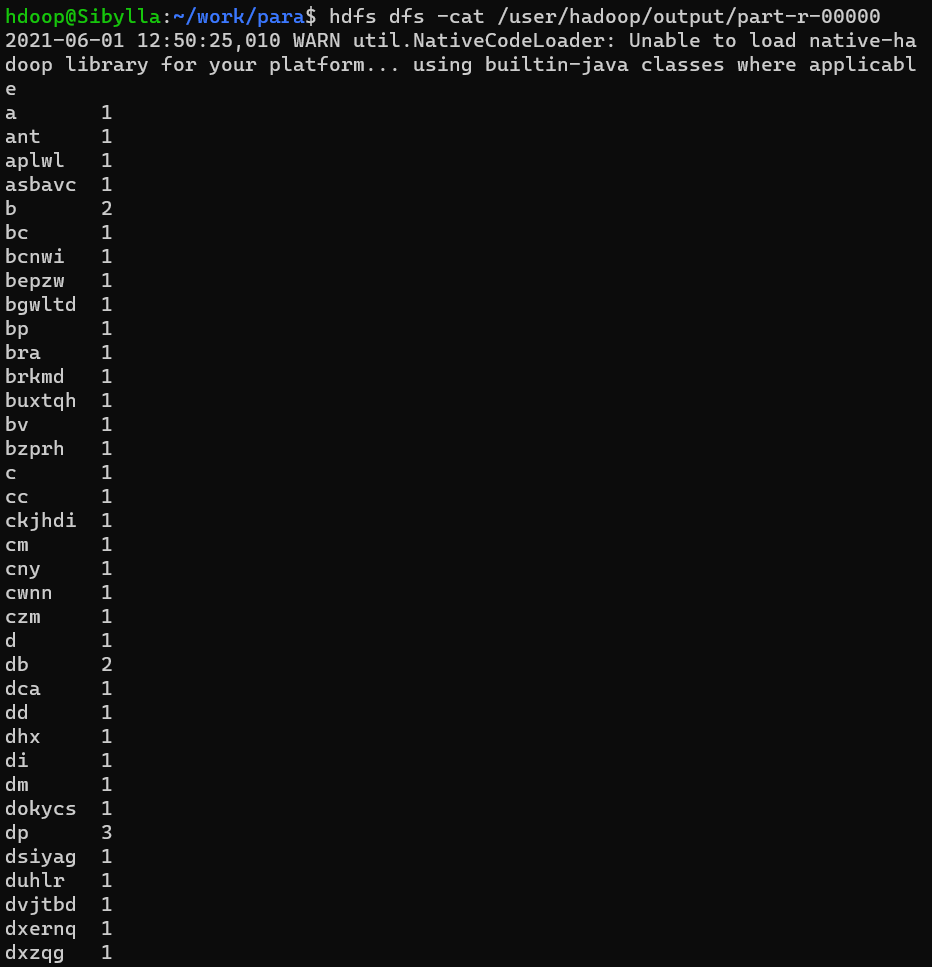
查看运行结果:
[WARNING] 即使是这么小的一个示例程序也几近将我的CPU和内存吞吃殆尽。
无关的碎碎念
本博客是在完成USTC2021春并行计算课程实验4的同时写成的。
最开始按照课程提供的祖传实验文档安装,不仅版本老旧过时,还出现了一众难以名状的错误。
后来助教提供了一篇新的文档,依旧运行失败(仅代表个人实践结果)。
再后来,我选择放弃参考学校这边的混沌文档,按照phoenixNAP的一篇文章最终安装成功(这篇文章除了.bashrc部分有些typo以外其他地方基本没有错误,是我安装和配置的主要参考)。